

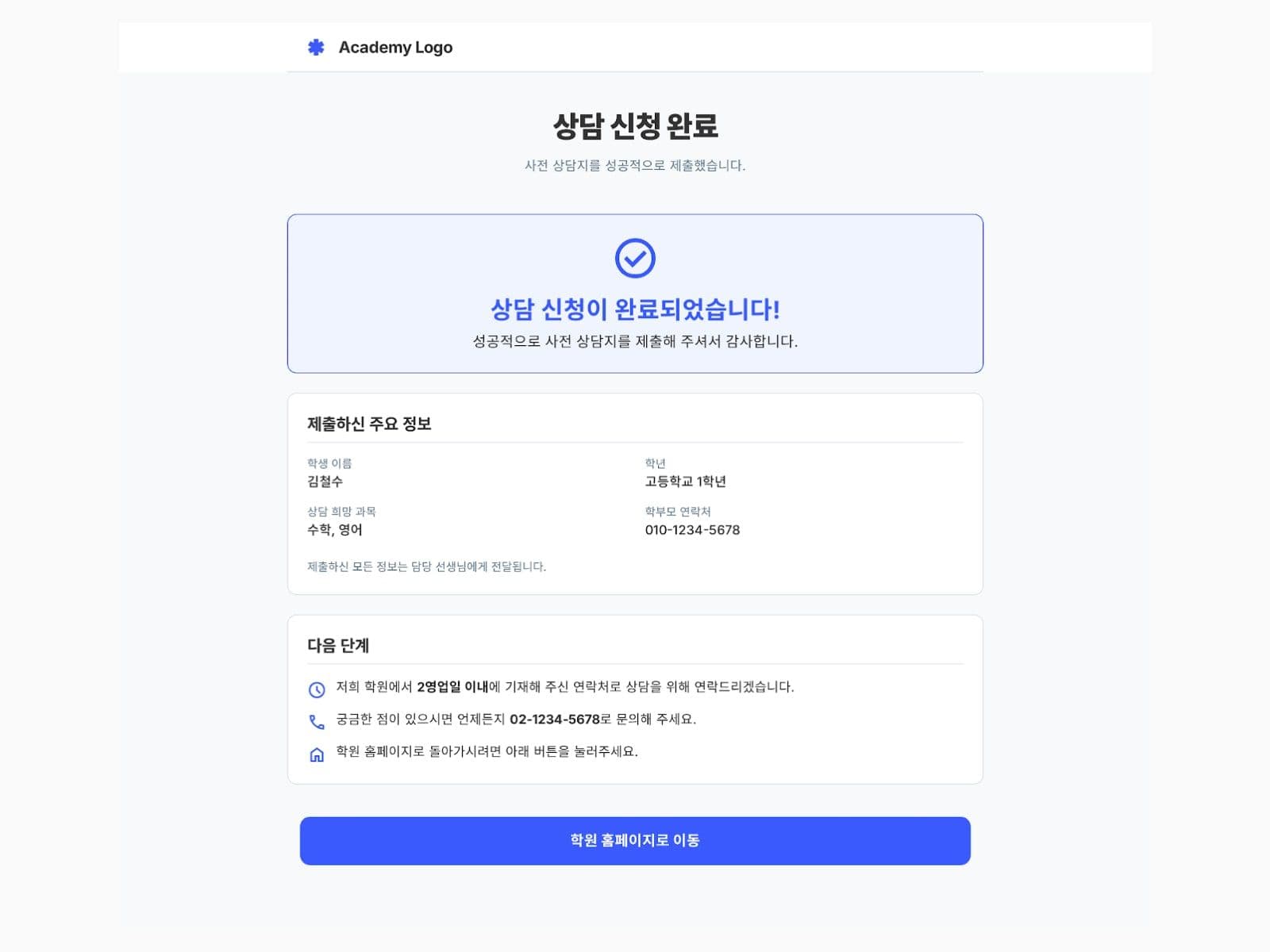
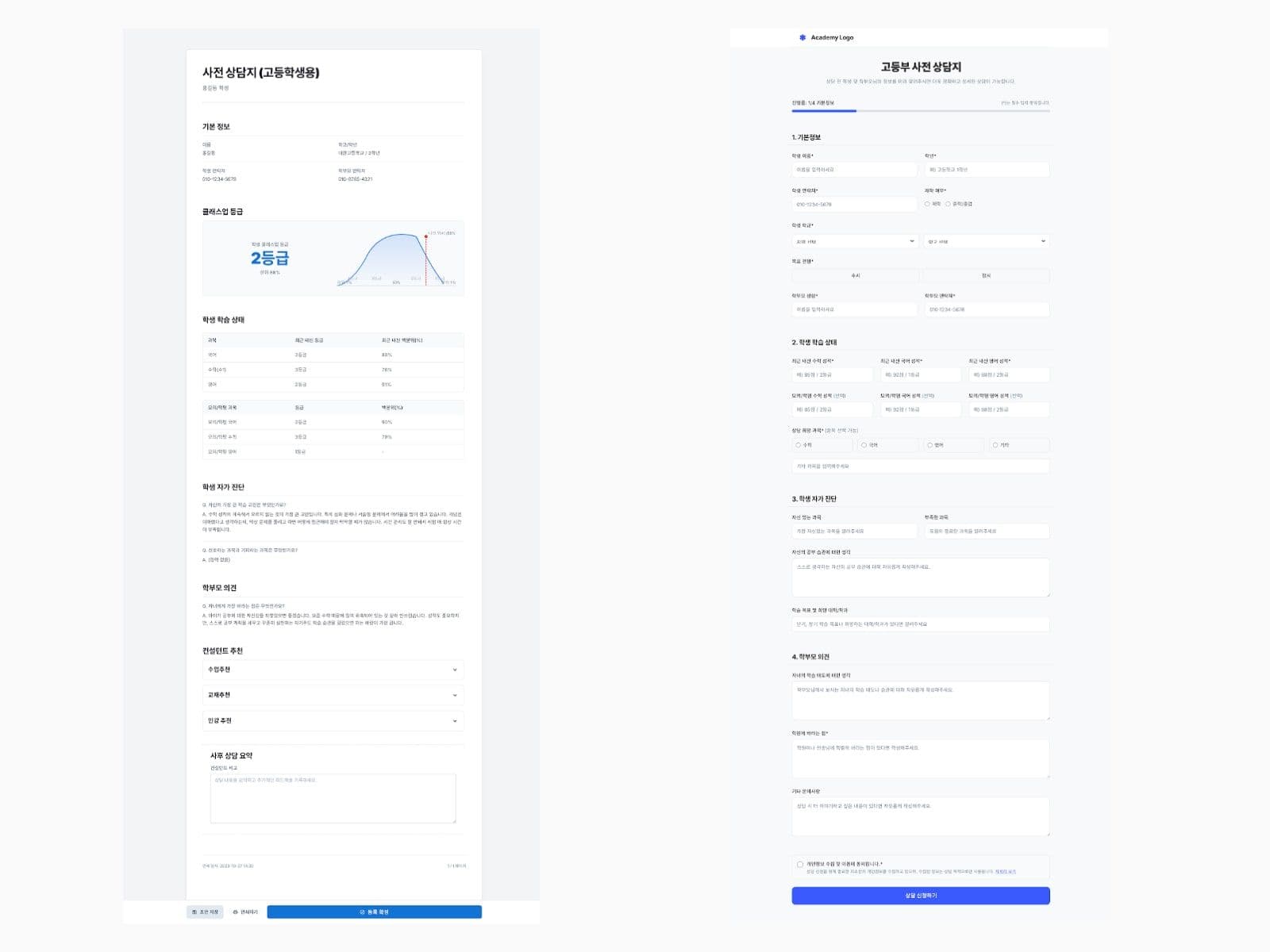
01·DOMAIN
정식 등록 전 상담 단계를 별도 모델로 분리
사전 상담 사용자는 아직 정식 회원이 아니지만, 상담 이후 등록으로 이어질 수 있는 데이터였습니다. 기존 회원 테이블에 바로 귀속시키기보다 temp_user 구조로 상담 단계를 분리했습니다.
tb_temp_user중심의 임시 사용자 구조 설계- 성적 정보와 상담 응답을 별도 테이블로 분리
- 추천 결과를 이후 등록 흐름과 연결 가능하게 저장
- 상담 단계와 정식 등록 단계를 자연스럽게 분리

